Web 3.0 有时被称为“语义网”、“3D 网”或“空间网”。它是关于使用新技术为内容添加意义并开发与我们的环境交互的方法。在语义网中,内容会找到你。与您根据关键字寻找信息不同,您的活动和兴趣将决定信息如何找到您以及您需要的格式,并将其显示在您的首选渠道中。
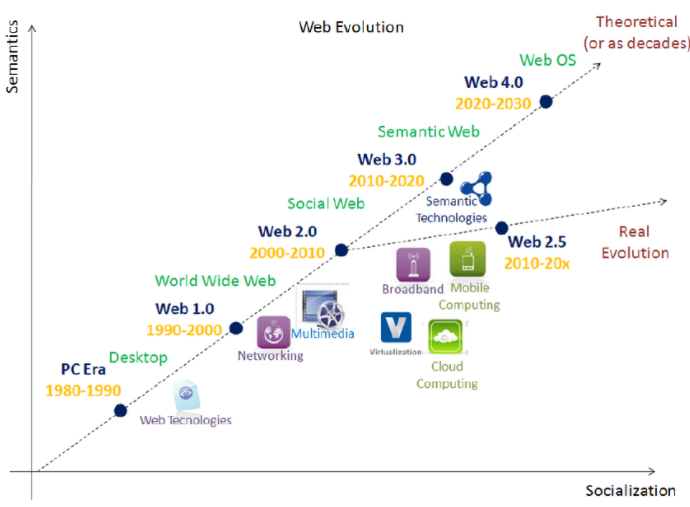
Web 3.0 建立在早期阶段:
Web 1.0 可以被视为“只读”——信息发布到用户可以阅读和搜索信息的网站,但没有机会轻松共享或与之交互。
Web 2.0 可以被认为是“读写”——它提供了社交网络工具,例如博客和维基。它专注于将人们聚集在一起、分享知识和促进沟通的能力。它还有助于协作学习和团队合作。
Web 1.0 和 Web 2.0 的问题在于信息是混乱和非结构化的,限制了检索相关和准确信息的能力。Web 3.0 承诺解决这些问题。
以下是一些将改变用户查找信息方式的关键发展的简要总结。
人工智能是可以自我学习和进化的自学习程序,例如,跟踪用户的习惯并提供适合他们偏好的搜索结果。
用户将能够输入他们的偏好和兴趣,计算机将自定义并提供符合这些标准的信息——用户配置文件将像一个虚拟化身一样在网上代表他们和他们的兴趣。
物联网是日常设备与互联网的连接。例如,配备传感器和联网的设备,如办公设备、打印机和车辆。这意味着用户将能够连接到互联网并从任何地方管理信息。
用户可以使用虚拟环境和增强现实与他们的环境进行交互——搜索结果不限于纯文本输入——您可以通过 3D 对象或图像按输入进行搜索。物理世界可以与数字和物理层融合的智能眼镜和语音等界面进行交互。
在 Web 3.0 中,计算能力不仅限于提供内容的几个中央服务器。相反,计算能力在多个服务器之间共享。这方面的一个例子是区块链技术,其中信息分布在许多设备上。这意味着信息可以非常安全地保存,并且不依赖于单个提供商。
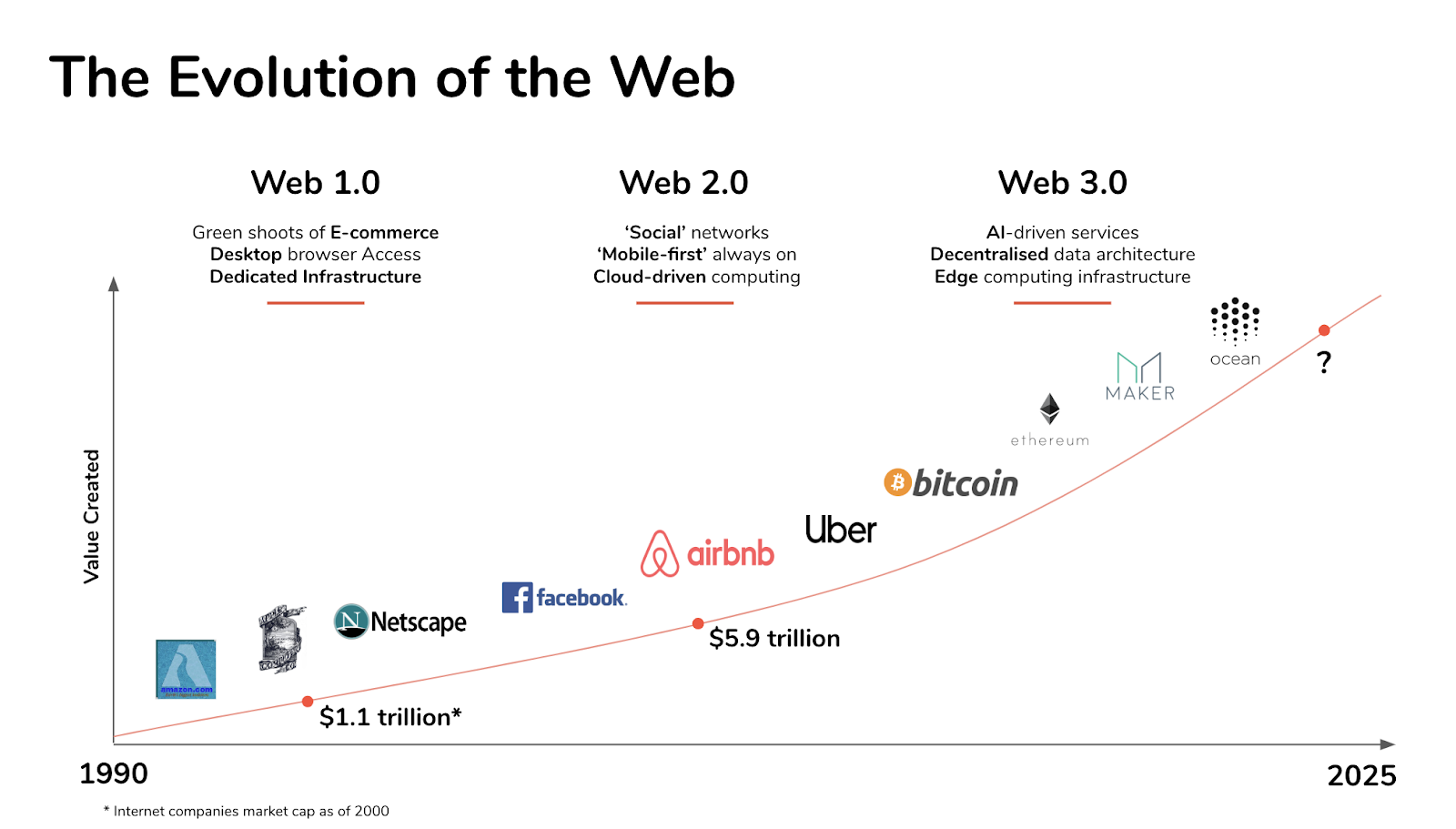
今天的网络浏览器在发现可能有用或有价值的信息之间的联系方面能力有限。一个标准的谷歌搜索会产生数百个结果,其中许多是不相关的或无关紧要的。
借助 Web 3.0,标准将使用标签或字段创建结构化的在线内容,使浏览器能够更轻松地识别和理解信息的含义。这需要将在线信息翻译成“微内容”。
为此,内容管理者将需要添加元数据描述,以赋予网站内容意义并描述有关它的现有知识的结构。因此,内容将更有效地搜索和互连。
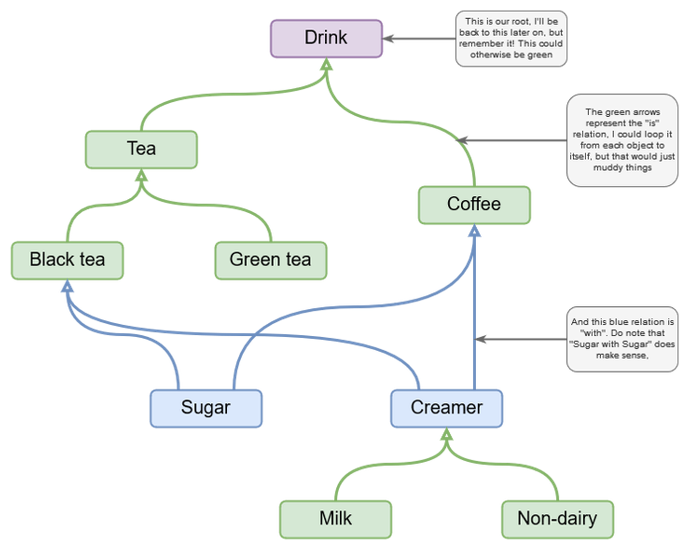
除了标记内容外,还有多种方法可以创建内容之间的关系——称为本体。Protégé由斯坦福大学开发,是一个免费的本体编辑器,可以使用OWL 2 Web Ontology Language创建这些连接。
下图显示了一个简单的本体示例——在这种情况下,它显示了如何为与不同类型饮料相关的内容赋予意义。
Web 3.0 将具有自然语言搜索功能,使用户能够提出完整的问题,而不是孤立地提出短语。目前,搜索引擎训练我们成为优秀的关键词搜索者——我们降低了我们的智力,以便它对计算机来说是自然的。最大的转变将是让计算机处理人类自然的表达方式。
借助 Web 3.0,更轻松、更快速地查找信息的能力有很多好处,但也有一些缺点。一、好处:
由于机器将连接互联网并提供对知识的访问,因此降低了费用。
教学变革 ——教师将能够开发由各种资源支持的引人入胜且更复杂的作业。学生将发展出更多的独立性,这将使教师可以自由地辅导个人或小组。将从学生消费教师提供的内容转变为学生创造内容。
学习——学生将花费更少的时间收集和整合知识。如果他们可以访问互联网,他们将能够随时随地学习。
知识构建——搜索引擎将产生一份来自许多来源的报告。该报告还将比较和对比所提供的信息,并暗示不同的论点,并提醒用户注意相关的主题和资源。
智能搜索——定制的搜索功能将只产生为用户量身定制的信息,防止挫败感并节省时间。搜索引擎将包括讲义、资源、视频、博客文章等。
个人学习网络维护——个人学习代理将搜索与学习目标相关的信息并仅报告相关信息。基于位置的服务将发送适当的信息。
个人教育管理——使用语义网来描述课程和学位,这样可以很容易地转移学分,学生可以很容易地确定能够为他们提供他们所寻求的知识的大学。电子学习和即时学习变得司空见惯。人们可以与分散的个人协作和互动。教育内容可以在需要许可的情况下使用和重复使用。
对学生学习的影响——学生花在收集信息上的时间更少,但这些都是重要的技能。向学生展示已经综合的信息,无需批判性思维、评估和论证。例如,当引入计算器时,人们期望学生从手工计算中解放出来,以便他们可以专注于解决方案。对于从事高级学科知识的学生来说确实如此,但如果过早引入,它们会阻碍基本数学技能的发展。
标记信息——谁将标记内容并向网页添加额外的编码?这需要大量的时间和资源。
开发者偏见——开发者的偏见和观点很可能会进入标签信息。即使是细微的调整也可能会消除一些相关信息或包含仅对开发人员重要的信息。
信息安全和隐私——用户偏好和在线行为可能会被错误地解释,并以用户不希望的方式过滤他们的信息。
审查和隐私问题——大量个人数据将在互联网上。数据抓取意味着可以从网页中提取数据并将其用于得出与作者预期完全不同的结论且无需注明作者的文章。如果内容没有编码,它可能会被 Web 3.0 浏览器忽略,并且不会成为特定主题领域内容知识的一部分。
Web 3.0 承诺允许用户以更有意义和更有效的方式查找信息并与之联系,但是学生培养自己研究和理解信息的技能的方式代价是什么?了解 Web 3.0 的优缺点是了解我们如何利用其优势的起点,同时要防止学生不熟练并降低他们自己辨别信息价值的能力的潜在劣势。

网友 : Hi there! Would you mind if I share your blog with my
zynga group? There's a lot of folks that I think would really enjoy your content.
Please let me know. Cheers https://evolution.org.ua/ 网友:Hi there! Would you mind if I share your blog with my zynga group?
There's a lot of folks hat I think wpuld really enjoy your content.
Please let me know. Cheers https://evolution.org.ua/
2024-11-26 02:38:01 回复
Hi there! Would you mind if I share your blog with my
zynga group? There's a lot of folks that I think would really enjoy your content.
Please let me know. Cheers https://evolution.org.ua/
2024-11-26 02:37:47 回复